
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks

본격적인 논문 리뷰에 앞서 용어를 먼저 짚고 넘어갈 필요가 있습니다. 이 논문에서는 width, depth, resolution이라는 용어가 빈번하게 등장합니다. 각 용어의 의미는 다음과 같습니다.
width: convNet layer의 channel 크기
depth: convNet layer의
resolution: 입력 이미지의 해상도
또한 model scaling에 관한 논문인 만큼 baseline model이라는 말도 자주 등장합니다. 별도의 언급이 없다면 baseline model은 위 사진의 (a)에 해당하는 모델입니다.
Background
ConvNet의 accuracy를 높이기 위해 width, depth를 늘리는 방법이 흔히 사용되어 왔고 조금 드문 경우지만 resolution을 증사기키는 방법도 사용됐습니다. 하지만 ConvNet을 scaling up 하는 원칙 같은 방법론이 존재하지 않았으며 대부분의 연구가 width, depth, resolution 중 한 가지만 증가시켰습니다. 두 가지 이상의 요소를 증가시키는 것은 가능하지만 모든 경우의 수에 대한 실험이 필요했으며 이 경우에도 최적의 accuracy와 efficiency를 얻기 어렵습니다.
이에 본논문에서는 ConvNet을 scaling up 하는 방법론을 고안했고, depth, width, resolution을 동시에 비례적으로 스케일링할 것을 제안했습니다.
Problem Formulation


본논문에서는 scaling up의 대상이 되는 baseline model은 이미 주어진 조건이라고 가정합니다. layer의 종류 F는 실험에서 통제되어야 할 요소이며 위 식의 L, H, W, C가 실험의 관심 대상입니다. 본논문에서는 변수를 더 줄이기 위해 baseline model의 모든 layer는 scalin up 할 때 모든 축이 동일한 비율로 증가한다고 가정합니다. 즉, 본논문에서 다루는 문제는 변수 d, w, r에 대한 최적화 문제로 정의할 수 있습니다.
Observation
본논문에서는 두 가지 중요한 observation이 있었습니다.
1. width, depth, resolution을 scaling up 하는 것은 accuracy를 증가시킨다. 하지만 모델의 규모가 커질수록 accuracy 증가율이 감소한다.
2. ConvNet의 accuracy와 efficiency를 높이기 위해서는 width, depth, resolution의 균형을 잡는 것이 중요하다.


상단의 그래프는 baseline model의 width, depth, resolution만을 증가시킨 그래프입니다. 세 가지 경우 모두 accuracy가 증가하지만 모델의 규모가 커질수록 그 증가율이 감소합니다.
하단의 그래프는 d와 r을 고정하고 w를 변화시키며 accuracy를 측정한 그래프입니다. 같은 FLOPS라도 d와 r을 함께 증가시킨 것이 더 정확도가 높음을 알 수 있습니다.
Compound Scaling

위의 두 가지 observation을 바탕으로 본논문에서는 d, w, r을 상수 a, b, c에 의해 결정하는 compound scaling을 제안했으며 상수 a, b, c는 규모가 작은 baseline모델로부터 실험을 통해 알아내는 값입니다.
EfficientNet
scaling up은 baseline model의 layer 종류에는 변화를 주지 않습니다. 따라서 모델의 성능을 높이기 위해서는 적절한 baseline model을 선택하는 것도 중요합니다. 본 논문에서는 NAS(Neural Architecture Search)를 통해 찾은 최적 모델을 baseline model인 EfficientNet-B0로 사용했습니다.

위와 같은 과정을 거쳐 compound scaling에 사용될 상수 a, b, c를 결정하고 baseline model을 scaling up 한 추가적인 모델 7개를 만들었습니다.
Experiment

위 표는 MobileNets와 ResNet을 baseline model로 설정하고 d, w, r 중 한 가지만 scaling up 했을 때와 compound scaling 했을 때의 FLOPS와 ImageNet에 대한 Top-1 Accuracy를 측정한 결과입니다. 비슷한 FLOPS임에도 compound scaling일 때의 accuracy가 더 높음을 확인할 수 있습니다.
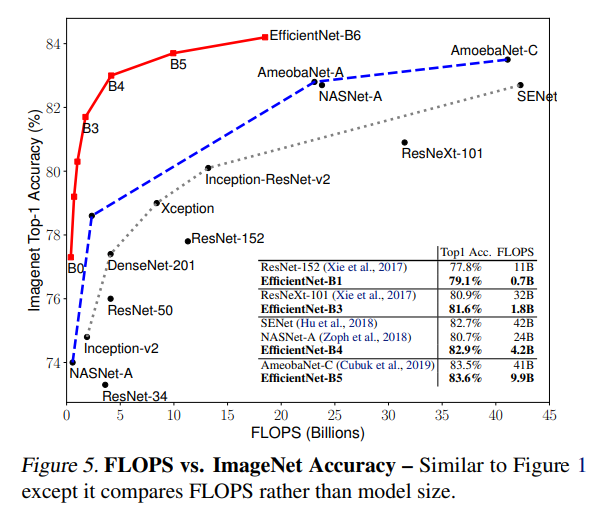
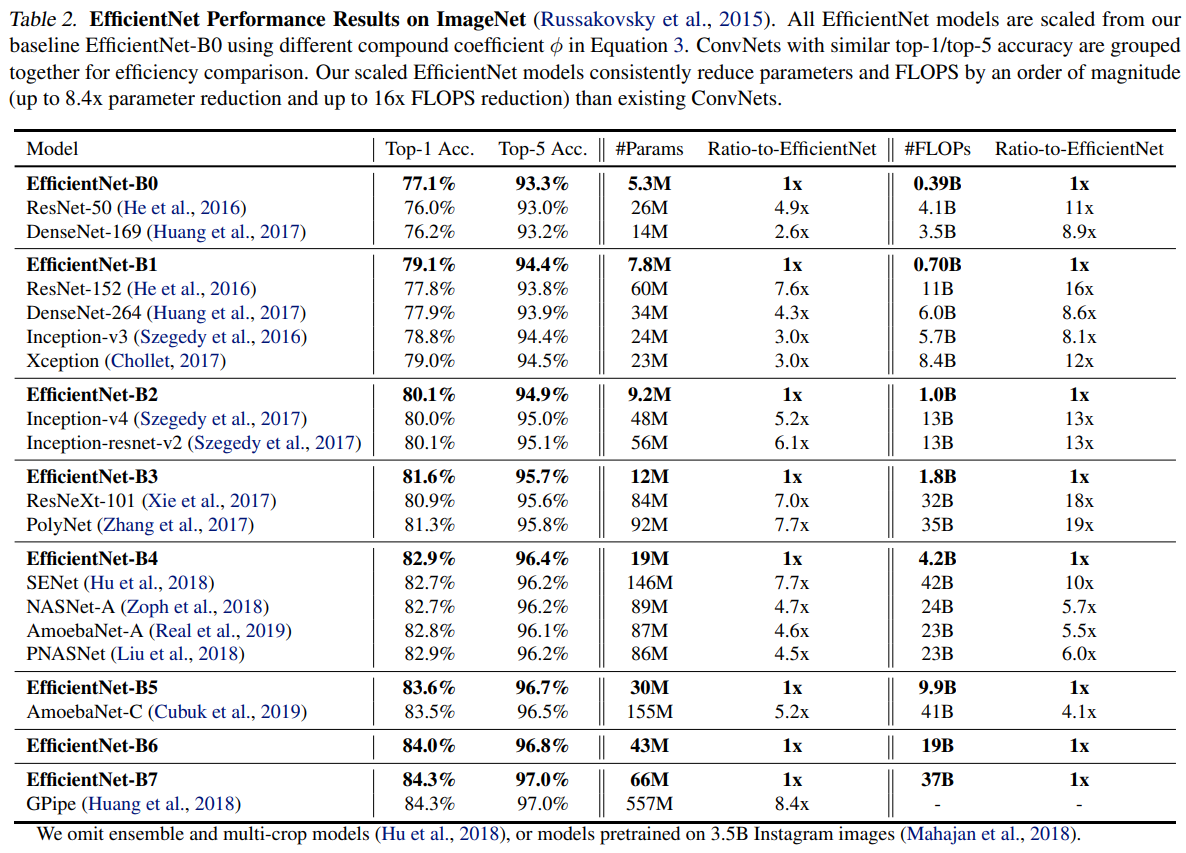
위 표는 NAS로 찾은 최적 모델을 baseline model과 이를 compound scaling 한 모델들의 ImageNet에 대한 Top-1 Acc와 Top-5 Acc과 FLOPS를 기록한 표입니다. 유사한 accuracy를 기록한 모델들과 비교했을 때 params, FLOPS 모두 EfficientNet이 더 적음을 알 수 있습니다.

위 표와 그래프는 EfficientNet을 전이학습시켜 다른 데이터셋에 적용한 결과를 기록했습니다. 8개의 데이터셋 중 5개의 데이터셋에 대하여 평균 9.6배 더 적은 파라미터를 사용해 더 높은 accuracy를 기록하였습니다.


위 그림은 baseline model과 scaling 방법에 따른 CAM을 나타낸 것입니다. 다른 모델들에 비해 compound scaling을 거친 모델에서 더 관련성 높은 영역과 객체 특징에 주목함을 알 수 있습니다.
