
Wide Residual Networks (2016)
https://arxiv.org/pdf/1605.07146
[요약]
- Deep residual network를 수천 층으로 scale해 성능 개선 가능하지만 개선하려는 정확도 퍼센트 당 두 배의 층이 필요 -> 훈련 속도 매우 느려짐
- Residual network의 깊이를 줄이고 너비를 넓혀 성능 개선 (Wide Residual Networks(WRNs)) – sota 달성
Ex) 간단한 16층 WRN이 정확도와 효율성 측면에서 과거 모든 deep ResNet 뛰어 넘음
[Introduction]
- increase in the number of layers in CNNs -> improvements in image recognition tasks
- but training deep networks has several difficulties: exploding/vanishing gradients and degradation
- up to this point, the study of residual networks focused mainly on the order of activations inside a ResNet block and the depth of residual blocks
-> Q. how do aspects other than the order of activations affect performance?
1. Width vs depth in residual networks
-깊은 학습 가능하게 하는 identity shortcut은 동시에 deep ResNet의 약점이 될 수 있다는 점에 초점 (shortcut 때문에gradient가 residual branch를 거치지 않아 일부 블록이 충분히 학습되지 않는 문제 발생 가능)

2. Use of dropout in ResNet blocks
- 통상적으로dropout (레이어 출력값 일부를 0으로 만들어 모델이 특정 feature에 과도하게 의존하는 것 방지 - > 학습 안정화하는 테크닉) 대신 batch normalization (레이어 출력값 분포 정규화 - > 학습 안정화) 사용 (정확도 더 좋았기 때문)
- WRN에서는 wider -> more parameters -> 과적합 위험 증가
-> WRN + dropout 제안
단 , 이전 연구 성과 좋지 않았던 identity shortcut에 dropout 넣는 것 아니라 residual branch 안에 넣자 : figure 1 (d)
[Wide residual networks]
논문에 나오는ResNet 블록 종류
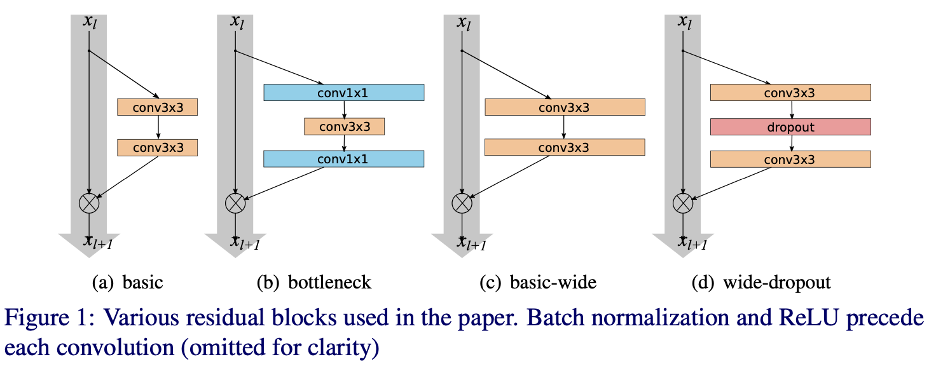
(a) basic: 3x3 convolution 두 개 (k=1)
(b) bottleneck: 가운데를 좁게 만들어서 (채널 수 줄여서) 계산량 감축
(c) basic-wide: 형태 basic과 같지만 깊게(deep) 가는 대신 가로로 넓게(wide) 키움
(d) wide-dropout
WRN 구조

- 기존 구조의 순서인 Conv-BN-ReLU가 아닌 BN-ReLU-Conv로 순서를 변경 (better results and faster training)
- 실험에서는 conv1 크기 고정, conv2,3,4의 widening factor k 조절하여 residual block의 representational power 측정
[Experimental results]
Image classification datasets: CIFAR, SVHN, ImageNet
1) Type of convolutions in a block: 3x3 conv

2) Number of convolutions per block: 2개

3) Width of residual blocks:
- k 늘릴수록 에러 감소 but 항상 그렇지는 않음

결과
1. ResNet너비를 넓히는 것은 깊이에 상관없이 퍼포먼스 개선
2. 깊이와 너비를 모두 증가시키면, 파라미터 수가 너무 많아지거나 더 강한 regularization이 필요해지기 전까지 좋은 결과를 보임
3. WRN은 얇은 네트워크보다 두 배 이상의 매개 변수를 사용하여 성공적으로 학습 가능
4. residual block에 dropout을 넣었을 때 CIFAR, SVHN에서 테스트 오류가 줄고 과적합 완화되었음

베스트 퍼포먼스 결과 정리

[결론]
Residual networks do not need to be extremely deep. Proper widening yields better accuracy–efficiency trade-off.
