
ResUnet: https://arxiv.org/pdf/1711.10684
Unet: https://arxiv.org/pdf/1505.04597
Resnet: https://arxiv.org/abs/1512.03385
Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with
arxiv.org
0. Abstract
- 항공 이미지에서 도로를 추출하는 것이 연구 주제
- Residual Learning: Residual Unit을 사용하여 입력과 출력 사이의 잔차를 학습하여 깊은 모델에서도 학습 가능하게. 학습이 쉬움.
- U-Net: 이미지의 크기를 줄였다가 (encoding) 키우는 (decoding) 구조를 가지고 Skip connection을 사용한다.
- ResUnet : U-Net의 인코더-디코더 구조를 유지하며 내부를 일반적인 신경망 유닛 대신 Residual Unit으로 대체 -> 파라미터 수는 줄이며 성능은 더 뛰어남.
1. Introduction
road area extraction , road centerline extraction 중 road area extraction
모델이 깊어질수록 성능이 좋지만 vanishing gradients문제 등으로 학습이 어려워짐
-> 1. Resnet: Residual Learning (잔차학습)으로 깊은 네트워크의 학습
2. U-Net으로 skip connection
을 결합한 Deep Residual U-Net(ResUnet)을 제안
2. Metheology
2.1. Deep Resnet
2.1.1. U-Net: low level detail + high level semantic information
U-Net은 Data augmentation 때문만이 아니라 skip connection이 정보가 전파될 수 있는 path를 만들어 주어 Back-propagation을 돕는다.

2.1.2. Residual unit: Full-Pre activation
x_l, x_l+1: l번째 유닛의 입력과 출력
F: residual function
f: activation function
h(x_l): identity mapping function(typically x_l)

Full Pre-activation : BN-ReLU-conv로 이루어짐

2.1.3. Deep ResUnet : UNet + Residual learning

Encoding: 3개의 Residual unit. Pooling 없이 stride=2를 적용해서 unit별 feature map이 반
Bridge: Encoding과 Decoding 연결.
Decoding: segmatic segmentation으로 변환. 3개의 Residual Unit이나, 각 unit 진입 전 encoding 단계에서 가져온 Feature맵을 결합하는 과정(Skip connection 역할)

Unet은 층이 23개, ResUnet은 15개. 파라미터 적다.
cropping 불필요
2.2. Loss Function

W: 파라미터
s_i: ground truth segmentation
Net(I_i;W)와 정답 s_i 사이의 MSE를 손실 함수로 사용. 미분 가능한 다른 손실 함수를 사용할수도 있음(UNet의 pixelwise cross entropy)
2.3. Result Refinement
항공 사진은 아주 큰데 ResUnet은 224*224만 볼 수 있어서 잘라야 함 -> overlap하게 잘라 경계선 부분을 두 결과의 평균으로 계산하여 경계선 없이 부드러운 결과 생성
3. Experiments
3.1. Dataset
Massachusetts Roads Dataset (학습용 1108장, 검증용 14장, 테스트용 49장, 1500*1500)
3.2. Implementation details
원본 이미지(1500*1500)에서 224*224 patch를 무작위적으로 추출하여 총 30000개의 샘플을 생성했고 data augmentation X
GPU: NVIDIA Titan 1080
Mini-batch size: 8
Learning rate: 0.001로 시작하여 20 에포크마다 0.1배씩 감소.
-> 50 Epoch에서 수렴
3.3 Evaluation metrics
1픽셀만 틀려도 틀렸다고 하면 너무 빡세다 -> Relaxed precision and recall로 허용범위 rho=3픽셀 반경 이내면 정답으로 인정
Break-even points: Precision=Recall인 지점. precision-recall curve와 y=x의 교점
precision recall에 관한 설명: https://sumniya.tistory.com/26
분류성능평가지표 - Precision(정밀도), Recall(재현율) and Accuracy(정확도)
기계학습에서 모델이나 패턴의 분류 성능 평가에 사용되는 지표들을 다루겠습니다. 어느 모델이든 간에 발전을 위한 feedback은 현재 모델의 performance를 올바르게 평가하는 것에서부터 시작합니
sumniya.tistory.com
3.4. Comparisons
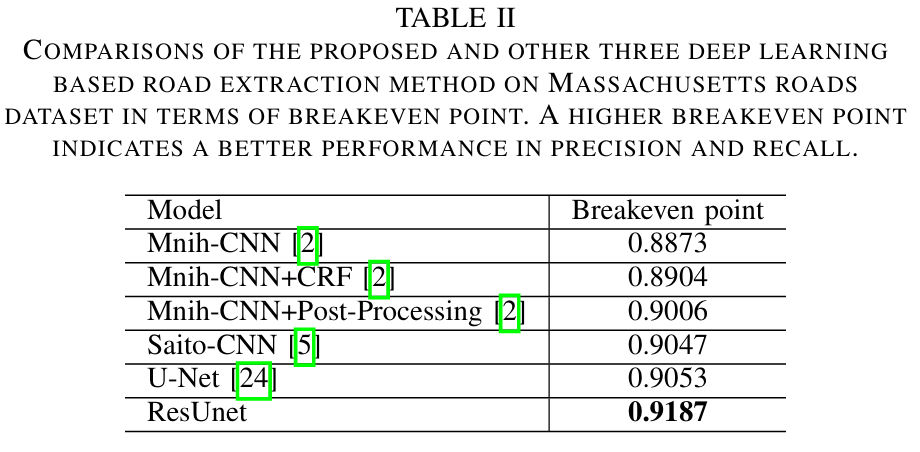
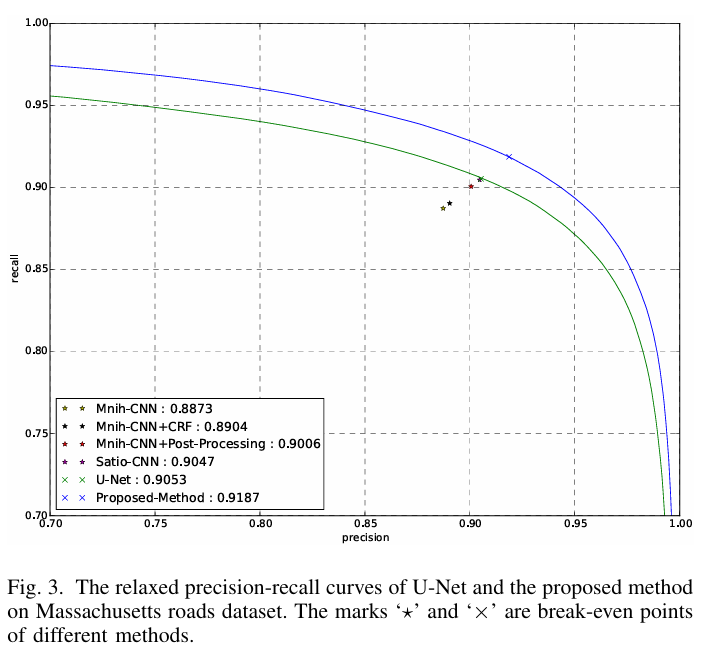
Breakeven point가 0.9187로 Mnih, Saito, U-Net보다 우수하다.
특히 파라미터가 ResUnet이 Unet의 1/4정도밖에 안되는데 더 우수함
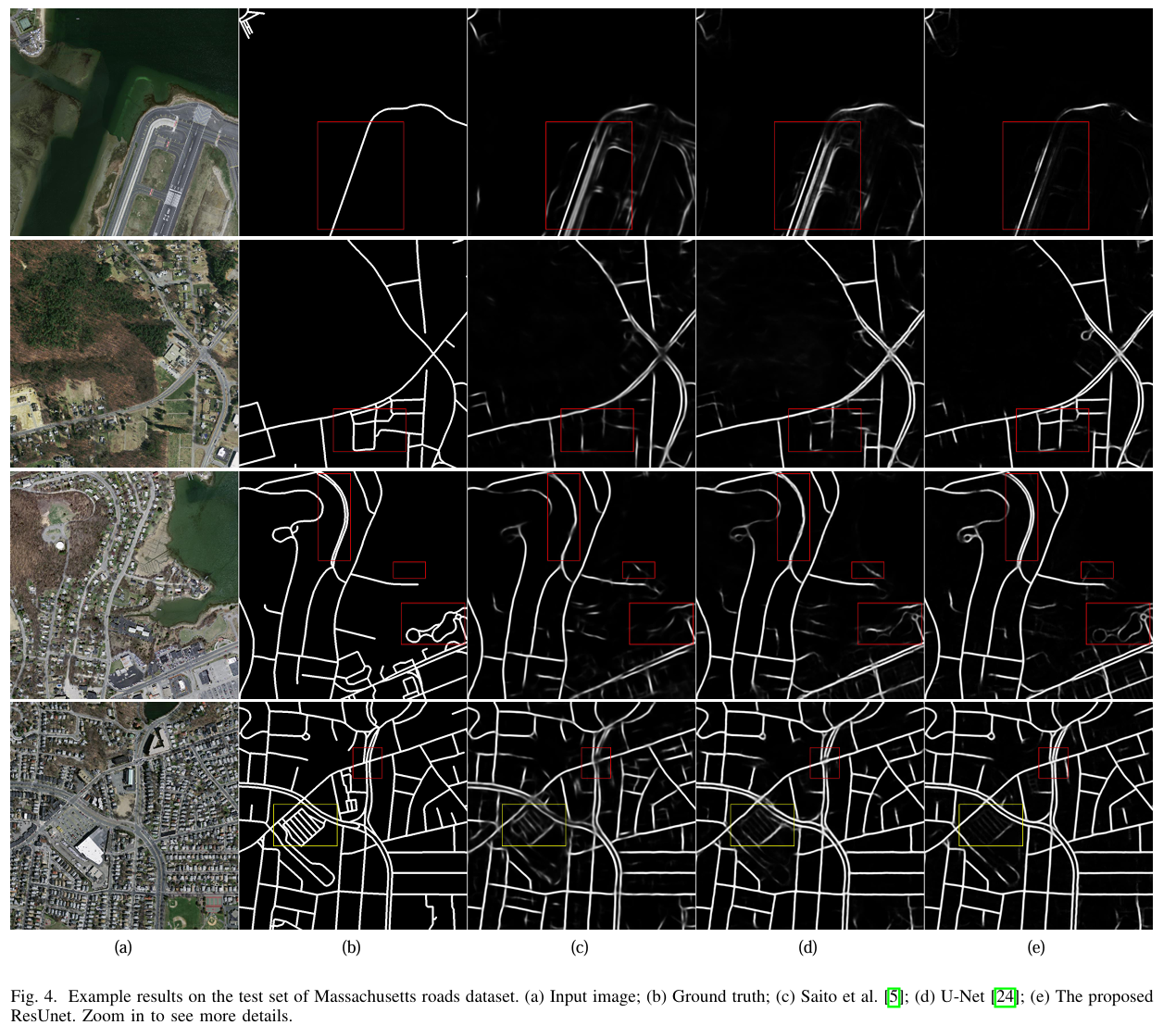
- ResUnet의 결과가 더 선명함
- 2차선의 도로를 하나로 뭉치지 않고 두줄로 인식함.
- 도로가 아닌 활주로는 무시함
- 나무로 가려진 길은 이어줌
4. Conclusion
ResUnet = Residual learning + Unet
Unet의 1/4 파라미터로도 Unet보다 우수한 성능을 보였다.
