IP-Adapter
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Ye et al., 2023
arXiv preprint only
1,700+ citations
https://arxiv.org/abs/2308.06721
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Recent years have witnessed the strong power of large text-to-image diffusion models for the impressive generative capability to create high-fidelity images. However, it is very tricky to generate desired images using only text prompt as it often involves
arxiv.org
1. Backgrounds
우리가 Stable Diffusion 방식 등의 AI에게 그림을 그려달라고 할 때, 보통은 글(텍스트)로 설명함
하지만 내가 머릿속에 그린 그 '느낌'이나 '스타일'을 글로 다 표현하기는 정말 어려움
-> "이 사진이랑 비슷한 느낌으로 그려줘!"라고 사진(이미지 프롬프트)을 보여주는 방식이 필요해짐
전체 미세 조정 방식
SD Image Variations: 원래 Stable Diffusion은 텍스트를 보고 그림을 그리는데, 이 모델은 텍스트 특징을 CLIP 이미지 임베딩으로 대체하여 사진만 보고 그림을 그리도록 모델 전체를 Fine-tuning함
기존: Attention1(Q, [text])
SD Image Variations: Attention2(Q, [text+image])
이 방식의 문제점
- 너무 무거움: 사진 기능을 넣으려면 AI 모델 전체를 다시 학습시켜야 함
- 호환성 제로: 모델 하나를 학습시켜도, 커스텀 모델들에는 적용할 수 없음
- 글을 무시함: 사진 기능을 넣었더니, 정작 텍스트 설명을 잘 못 알아듣게 됨
연구 아이디어
<AI 모델 자체를 뜯어고치는 대신, 'IP-Adapter'라는 아주 가볍고 효율적인 연결 잭(어댑터)을 만들자>
어댑터가 무엇인가?
거대한 AI모델 전체를 새로 학습시키는 대신, 아주 작은 일부 부품만 추가하여 새로운 기능을 넣는 기술
원래 모델은 그대로 Freeze한 채, 추가된 소수의 learnable한 파라미터만 훈련시켜 효율적으로 성능을 끌어올림
NLP 분야에서는 오래전부터 사용되어 왔으나, 이미지 생성에서는 아직 미세 조정 방식만큼의 성능을 못내고 있음
기존 어댑터 방식
T2I-Adapter: 사진에서 특징을 뽑아낸 뒤, 그걸 텍스트 데이터 뒤에 꼬리표처럼 붙여서 하나의 통로로 한꺼번에 밀어 넣음
F = Adapter([Image]) <- CNN 기반 네트워크로 특징 추출
U-Net decoder path의 중간 feature Z에 Z' = Z + F
이 방식의 문제점
- 표현력 부족: 이미지 정보를 텍스트 통로에 억지로 구겨 넣으면서 정보가 소실됨
- Fine-tuning 방식과 달리 어댑터는 겉핥기식으로만 이해를 하여 결과물이 엉성함
2. Preliminaries
2.1 Cross-Attention 메커니즘
U-Net이 텍스트 특징을 처리하도록 하기 위해 Attention 메커니즘을 사용함
쿼리(Q), 키(K), 값(V)을 사용하여 다음과 같이 연산함

Q = Z W_q: 이미지의 중간 특징임
K = c W_k, V = c W_v: 조건 c(텍스트 특징)에서 추출한 Key와 Value임
이 연산을 통해 AI는 그림의 어느 부분에 텍스트의 어떤 단어를 반영할지를 결정함
2.2 노이즈 예측 학습
데이터 x_0에 노이즈 epsilon을 섞은 뒤, 모델 epsilon_theta가 노이즈를 예측하도록 학습함
학습 시 사용되는 손실 함수는 아래와 같음

x_t: 시간 t에서의 노이즈가 섞인 이미지. x_t = sqrt(alpha_t) x_0 + sqrt(1 - alpha_t) epsilon으로 계산됨
c: 텍스트나 이미지 같은 조건임
epsilon_theta: U-Net이 예측한 노이즈. 실제 섞인 노이즈 epsilon과 예측치의 차이를 줄이는 방향으로 학습됨
2.3 분류기 없는 가이드 (CFG)
학습된 모델이 사용자의 조건 c에 더 민감하게 반응하도록 만드는 기술임
추론 단계에서 예측 노이즈 epsilon_theta_hat을 아래와 같이 계산함

w (Guidance Scale): 이 값이 클수록 c(이미지 프롬프트 등)의 특징이 결과물에 강하게 나타남
epsilon_theta(x_t, t): 조건 없이 생성한 노이즈 예측값임
3. Methodology
IP-Adapter의 목표는 기존 텍스트 기반 모델에 이미지 경로를 추가하되, 텍스트 정보를 오염시키지 않는 것
우선 CLIP을 인코더로 하여 이미지 안에 담긴 의미를 추출하여 embedding 벡터로 만들고,
Projection Network를 거치게 하여 UNet에 입력 가능한 형태가 되도록 차원 일치, 토큰화함
"분리된 Cross-Attension"
기존 방식: K와 V에 텍스트와 이미지를 합쳐서 넣음 -> 정보가 섞이고 성능이 저하

IP-Adapter: 텍스트용 부품과 이미지용 부품을 별도로 둠

Q: 이미지에서 추출된 중간 특징
K, V: 텍스트 정보에서 나온 Key, Value
K', V': 이미지 정보에서 나온 새로운 Key, Value
기존: Attention1(Q, [text])
SD Image Variations: Attention2(Q, [text+image])
IP-Adapter: Attension1(Q, [text]) + Attension3(Q, [image])
왜 이렇게 하나?
- 기존 모델의 파라미터는 Freeze하고 K'와 V'를 만드는 작은 Linear layers만 학습시키면 됨
- 텍스트와 이미지 둘 다 자기 통로를 가짐. 이미지를 넣어도 텍스트를 무시하지 않게 됨
--> 모델이 매우 가벼우며(22M 파라미터), 학습 속도도 빠름
4. Training and Results
구현 방식:
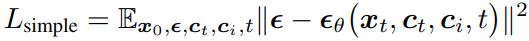

실험 결과:
IP-Adapter는 참조 이미지의 내용과 스타일을 동시에 가장 잘 유지했음

이미지 정렬도와 텍스트 정렬도 측정 결과, 모델 전체를 미세 조정한 Stable unCLIP보다도 IP-Adapter가 높은 점수를 기록함
Fig. 3~11 확인, 다양한 task에서 질적으로 우수한 결과 나옴



- 텍스트 프롬프트를 통해 이미지 프롬프트의 특정 속성을 수정할 수 있음
ex. 강아지 사진 + "해변에서 달리는(텍스트)"를 입력하면, 사진 속 강아지의 외형 그대로 동작만 바뀐 이미지가 생성됨
- SD v1.5 기반으로 학습된 IP-Adapter가 한 번도 본 적 없는 커스텀 모델에서도 즉시 작동함
- 구조 제어를 위한 다른 어댑터인 ControlNet과 동시에 사용할 수 있음
